

Surveillance systems rely heavily upon the capability provided by embedded vision systems to enable deployment across a wide range of markets and applications. These surveillance systems are used for numerous applications from event and traffic monitoring, safety and security applications, to ISR and business intelligence. This diversity brings with it several driving challenges which need to be addressed by the system designers in their solution. These are:
Multi Camera Vision – The ability to interface with multiple homogeneous or heterogeneous sensor types.
Computer Vision Techniques – The ability to develop using high level libraries and frameworks like OpenCV and OpenVX.
Machine Learning Techniques – The ability to use frameworks like Caffe to implement machine learning inference engines.
Increasing Resolutions and Frame rates – Increases the data processing required for each frame of the image.
Depending upon the application, the surveillance systems will implement algorithms such as optical flow to detect motion within the image. Stereo vision provides depth perception within the image, while machine learning techniques are also used to detect and classify objects within an image.
Heterogeneous System on Chip devices like the All Programmable Zynq®-7000 and the Zynq® Ultrascale+™ MPSoC are increasingly being used for the development of surveillance applications. These devices combine high performance ARM® cores to form a Processing System (PS) with Programmable Logic (PL) fabric.
This tight coupling of PL and PS allows for the creation of a system which is more responsive, reconfigurable, and power efficient when compared to a traditional approach. Traditional CPU / GPU based SoC approaches require the use of system memory to transfer images from one stage of processing to the next. This reduces determinism, increases power dissipation and latency of the system response, as multiple resources will be accessing the same memory creating a bottleneck in the processing algorithm. This bottleneck increases as the frame rate and resolution of the image increases.
This bottleneck is removed when the solution is implemented using a Zynq-7000 or Zynq UltraScale+ MPSoC device. These devices allow the designer to implement the image processing pipeline within the PL of the device. Creating a true image pipeline in parallel within the PL where the output of one stage is passed to the input of another. This allows for a deterministic response time with a reduced latency and power optimal solution.
The use of the PL to implement the image processing pipeline also brings with it a wider interfacing capability than traditional CPU/GPU SoC approaches, which come with fixed interfaces. The flexible nature of PL IO structures allows for any to any connectivity, enabling industry standard interfaces such as MIPI, Camera Link, HDMI, etc. The flexible nature also enables bespoke legacy interfaces to be implemented along with the ability to upgrade to support the latest interface standards. Use of the PL also enables the system to be able to interface with multiple cameras in parallel.
What is critical however is the ability to implement the application algorithms without the need to rewrite all the high level algorithms in a hardware description language like Verilog or VHDL. This is where the reVISION™ Stack comes into play.
 reVISION Stack
reVISION Stack
The reVISION stack enables developers to implement computer vision and machine learning techniques. This is possible using the same high level frame works and libraries when targeting the Zynq-7000 and Zynq UltraScale+ MPSoC. To enable this, reVISION combines a wide range of resources enabling platform, application and algorithm development. As such, the stack is aligned into three distinct levels:
- Platform Development – This is the lowest level of the stack and is the one on which the remaining layers of the stack are built. This layer provides the platform definition for the SDSoC™ tool.
- Algorithm Development – The middle layer of the stack provides support implementing the algorithms required. This layer also provides support for acceleration of both image processing and machine learning inference engines into the programmable logic.
- Application Development – The highest layer of the stack provides support for industry standard frameworks. These allow for the development of the application which leverages the platform and algorithm development layers.
Both the algorithm and application levels of the stack are designed to support both a traditional image processing flow and a machine learning flow. Within the algorithm layer, there is support provided for the development of image processing algorithms using the OpenCV library. This includes the ability to accelerate into the programmable logic a significant number of OpenCV functions (including the OpenVX core subset). While to support machine learning, the algorithm development layer provides several predefined hardware functions which can be placed within the PL to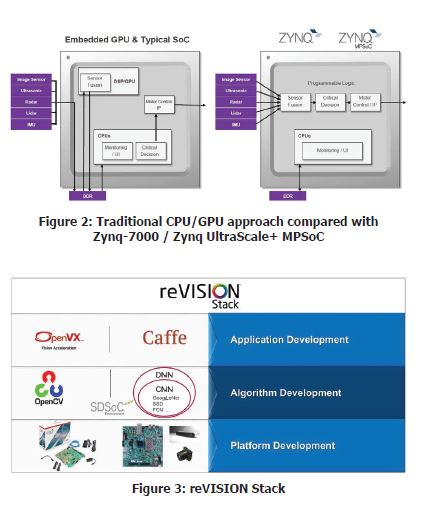 implement a machine learning inference engine. These image processing algorithms and machine learning inference engines are then accessed, and used by the application development layer to create the final application and provide support for high level frame works like OpenVX and Caffe.
implement a machine learning inference engine. These image processing algorithms and machine learning inference engines are then accessed, and used by the application development layer to create the final application and provide support for high level frame works like OpenVX and Caffe.
The capability provided by the reVISION stack provides all the necessary elements to implement the algorithms required for high performance surveillance systems.
Accelerating OpenCV in reVISION
One of the most exciting aspects of the algorithm development layer is the ability to accelerate a wide range of OpenCV functions within it. Within this layer, the OpenCV functions capable of being accelerated can be grouped into one of four high level categories.
- Computation – Includes functions such as absolute difference between two frames, pixel
 wise operations (addition, subtraction and multiplication), gradient and integral operations.
wise operations (addition, subtraction and multiplication), gradient and integral operations. - Input Processing – Provides support for bit depth conversions, channel operations, histogram equalisation, remapping and resizing.
- Filtering – Provides support for a wide range of filters including Sobel, Custom Convolution and Gaussian filters.
- Other – Provides a wide range of functions including Canny/Fast/Harris edge detection, thresholding and SVM and HoG classifiers.
These functions also form the core functions of the OpenVX subset, providing tight integration with the application development layer support for OpenVX. The development team can use these functions to create an algorithmic pipeline within the programmable logic. Being able to implement functions in the logic in this way significantly increases the performance of the algorithm implementation.
Machine learning in reVISION
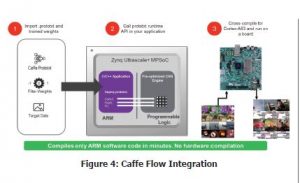
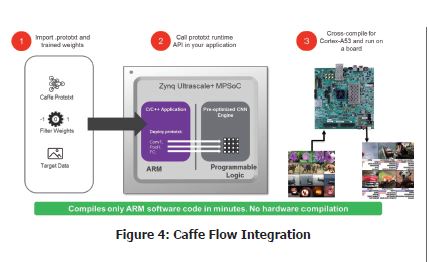
reVISION provides integration with Caffe providing the ability to implement machine learning inference engines. This integration with Caffe takes place at both the algorithm development and application development layers. The Caffe framework provides developers with a range of libraries, models and pre-trained weights within a C++ library, along with Python™ and MATLAB® bindings. This framework enables the user to create networks and train them to perform the operations desired, without the need to start from scratch. To aid reuse, Caffe users can share their models via the model zoo, which provides several network models that can be implemented and updated for a specialised task if desired. These networks and weights are defined within a prototxt file, when deployed in the machine learning environment it is this file which is used to define the inference engine.
reVISION provides integration with Caffe, which makes implementing machine learning inference engines as easy as providing a prototxt file; the framework handles the rest. This prototxt file is then used to configure the processing system and the hardware optimised libraries within the programmable logic. The programmable logic is used to implement the inference engine and contains such functions as Conv, ReLu, Pooling and more.
The number representation systems used within machine learning inference engine implementations also play a significant role in its performance. Machine learning applications are increasingly using more efficient, reduced precision fixed point number systems, such as INT8 representation. The use of fixed point reduced precision number systems comes without a significant loss in accuracy when compared with a traditional floating point 32 (FP32) approach. As fixed point mathematics are also considerably easier to implement than floating point, this move to INT8 provides for more efficient, faster solutions in some implementations. This use of fixed point number systems is ideal for implementation within a programmable logic solution, reVISION provides the ability to work with INT8 representations in the PL. These INT8 representations enable the use of dedicated DSP blocks within the PL. The architecture of these DSP blocks enables up to two concurrent INT8 Multiply Accumulate operations to be performed when using the same kernel weights. This provides not only a high-performance implementation, but also one which provides a reduced power dissipation. The flexible nature of programmable logic also enables easy implementation of further reduced precision fixed point number representation systems as they are adopted.
Conclusion
reVISION provides developers with the ability to leverage the capability provided by Zynq-7000 and Zynq UltraScale+ MPSoC devices. This is especially true as there is no need to be a specialist to be able to implement the algorithms using programmable logic. These algorithms and machine learning applications can be implemented using high-level industry standard frameworks, reducing the development time of the system. This allows the developer to deliver a system which provides increased responsivity, is reconfigurable, and presents a power optimal solution.
For more information, please visit: https://www.xilinx.com/products/design-tools/embedded-vision-zone.html
